

Written by
Margaret Jennings
Article
•
10 min
Begin by viewing your product as a collaboration tool, choose a persona, then use product surfaces to collect feedback for model training.
Large Language Models (LLMs) are highly malleable and have the ability to support a wide range of activities, from acting as a sounding board or coach to conducting highly repeatable tasks. However, designing a product where user interaction enables critical signal and feedback for model training can be challenging.
In this essay, I share notes from the field - an attempt to write down my thought process as we build a product that leverages AGI research models. There are three primary steps: identifying your collaboration category, collecting feedback data, and empowering a multidisciplinary team for future product decisions.
HOW TO BUILD A PRODUCT THAT LEVERAGES AGI RESEARCH MODELS
As more become interested in Generative AI, many are asking: what’s the best way to design a product that is powered by LLMs? The answer lies with how you intend to frame the product's value proposition and engage the user interaction to provide critical signal and feedback for model training.
That said - more I work with LLMs, the more I find the need to design for user control and trust. This topic of user adoption will be covered in my next essay.
STEP 1: CHOOSE A COLLABORATION TYPE
As previously stated, AGI is about accessing a set of skills that normally require decades of experience and mastery. At its best, AGI is a superior collaborator, asking the user to steer and refine the final output.
Your first step as a product builder in harnessing LLMs is to determine the type of collaboration you wish to support between the end user and research model. LLMs can be either task-oriented or open-ended, improving current practices or reimagining them entirely.
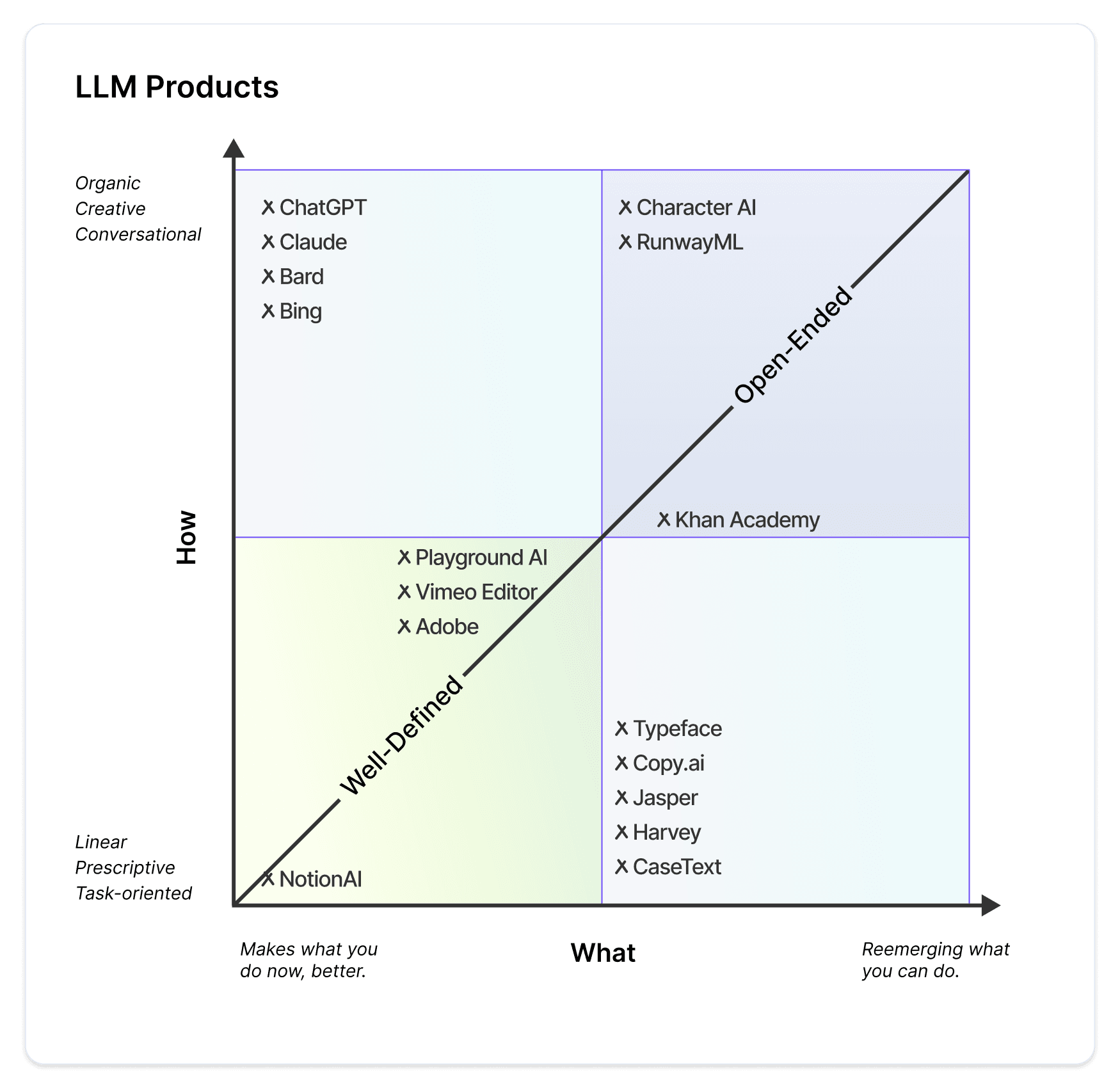
The following is a rubric to help you decide how you want to leverage LLMs. LLMs can be applied in wide variety of use cases, such as a feature within an existing process (Notion AI, Microsoft Copilot) or a standalone product (ChatGPT, RunwayML).
COLLABORATION RUBRIC
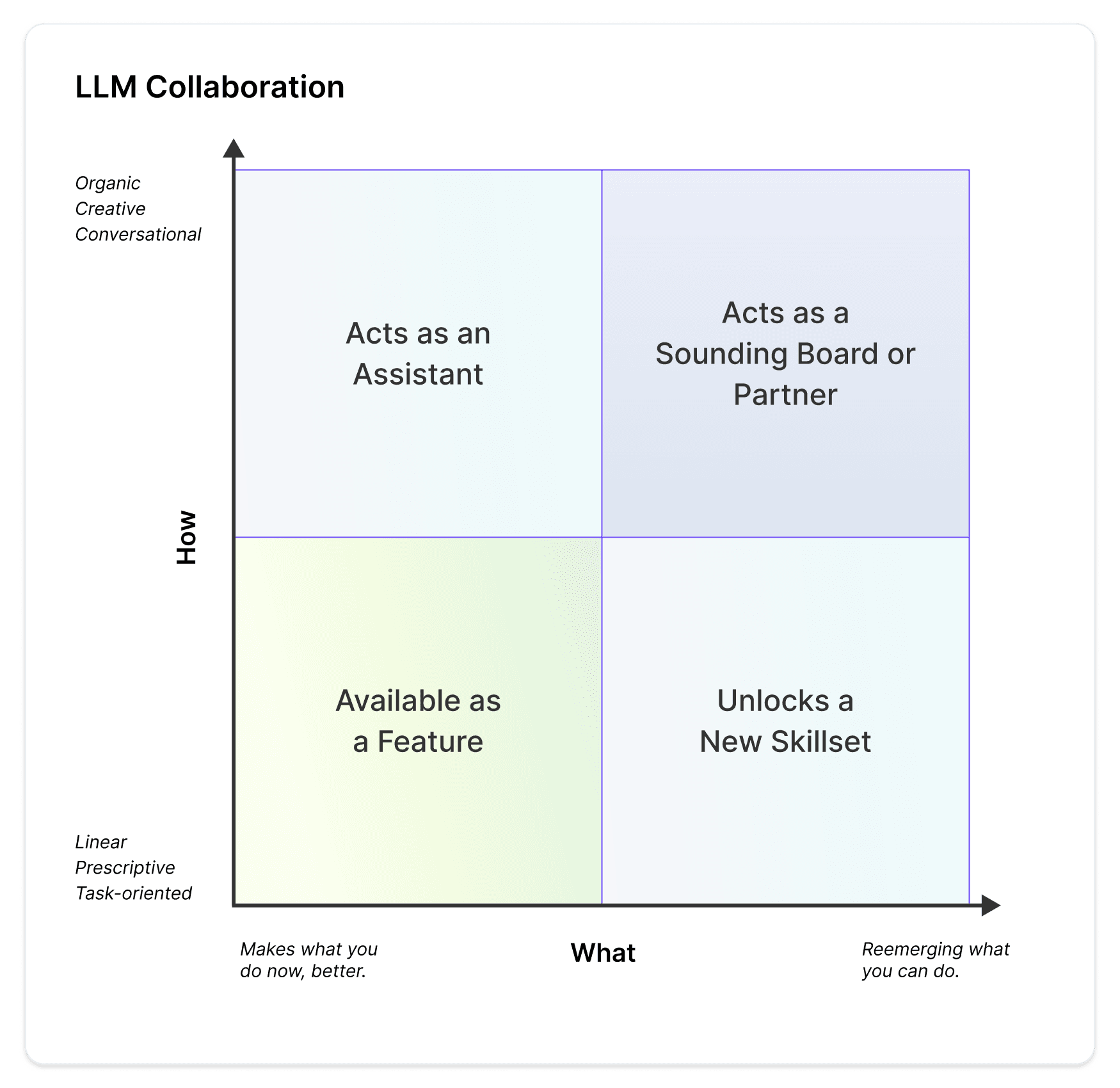
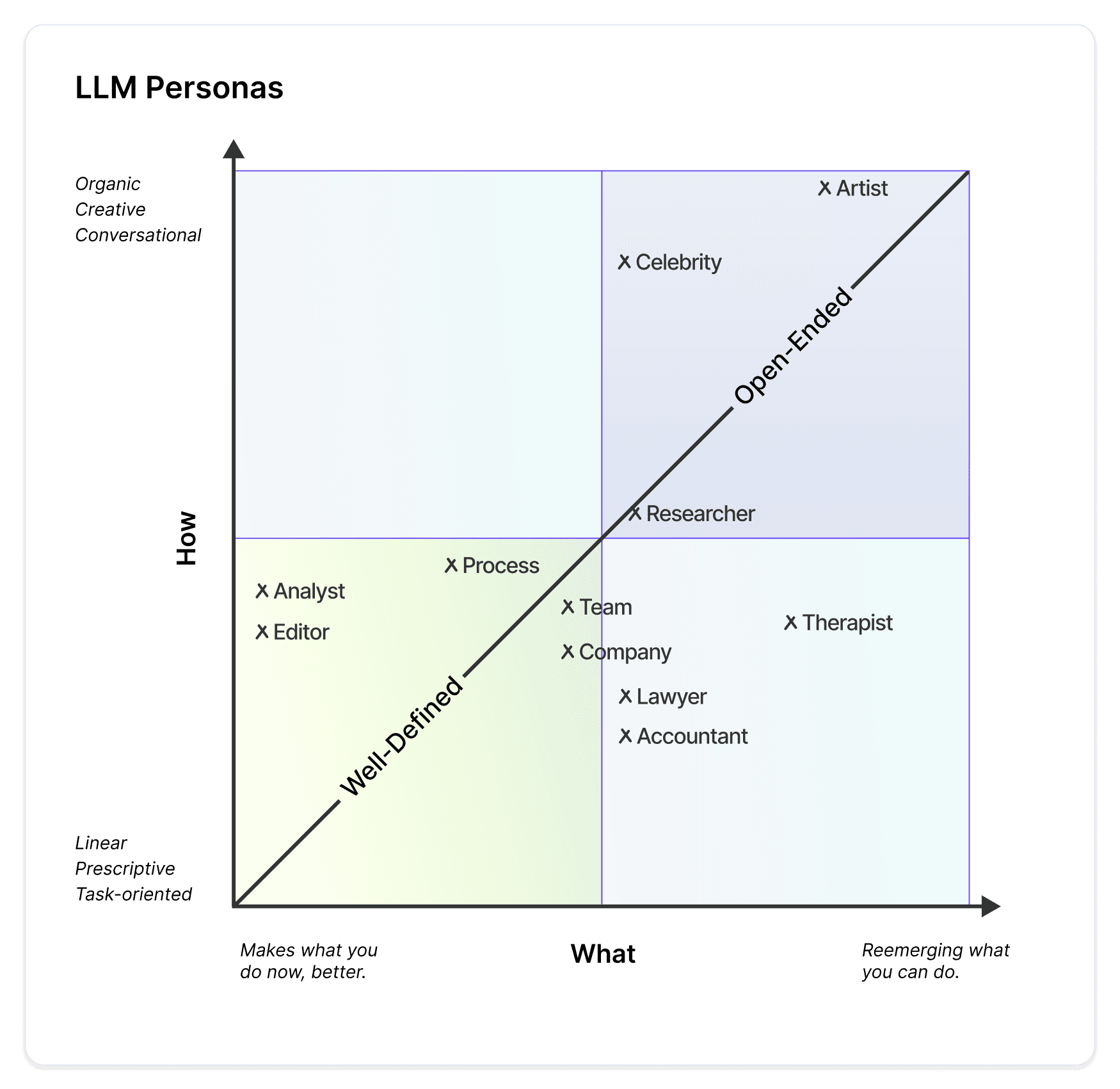
LLMs are multipurpose and can be programmed to support a spectrum of activities. Models are steered by prompts, which provide the model a persona to guide the model's ability to complete a task. Below is the same rubric populated by personas as well as products in the market to date.
On the left side, there are linear applications, whereby the LLM acts as a task-oriented agent, assistant, or specialist. This collaboration allows you to offload repeatable tasks aka enabling the LLM to do the unseen work of your day that most likely won’t get you promoted. These tasks include updating spreadsheets (Bard Demo at the Google IO), online research (Adept demo), or ordering groceries online (OpenAI Demo at TedX). (If you’re interested in reading more about AI and Unseen Work, I highly recommend Diana Forsythe’s paper “It's Just a Matter of Common Sense”: Ethnography as Invisible Work which includes an ethnography on AI Research Labs of the 90s and their value system of “visible” and “invisible” work).
On the right side there are open-ended applications, whereby the LLM acts as a sounding board, coach, or therapist. It can solve pain points or blockages in your creative process (Runway ML's Gen 2), serve as a source of inspiration (Character AI's persona building) or act as an analyst or writing assistant by generating your first draft (Notion AI).
CHOOSE A PERSONA
APPLICATIONS POWERED BY LLMs
STEP 2: YOUR CUSTOMERS ARE EXPERTS-IN-THE-LOOP SO BEGIN COLLECTING THEIR MODEL FEEDBACK
How you work and interact with the AGI models is critical IP for reinforcement learning. Where data moats were critical for Traditional AI, feedback data is critical for Generative AI.
Now that you’ve decided how you want the end user to collaborate with the research model, begin to think of your users as experts-in-the-loop who are helping you create better, more advanced models through their product usage.
In order to train LLMs specific to your product, the product surfaces will require collecting the end user’s input and feedback. Building and retraining LLM models comes from a subsection of deep learning called Reinforcement Learning Human Feedback (RLHF).
In research, RLHF typically requires human annotators to rank a model’s completion, which can be used to compare the outputs of multiple models and create a better, more regularized dataset. Research can often times be blocked when the model’s performance is only as good as the human annotator’s intuition on which behaviors look correct, so if the human annotator doesn’t have a good grasp of the task they may not offer as much helpful feedback (OpenAI’s Learning from Human Preferences and DeepMind’s Learning through Human Feedback).
Building a product with a compelling value proposition means that the end user is (hopefully) an expert in the task at hand and can provide valuable feedback on when the behavior looks correct or hallucinates. Product based LLM training - therefore - has a higher chance of quality feedback data to train LLM models.
Gamifying feedback: Databricks Dolly is an example where a company trained a model by gamifying their colleagues participation in drafting instruction following (IF) and facilitating evals to create a GPT3-like model and open source it for commercial and research use.
Free Dolly: Introducing the World's First Truly Open Instruction-Tuned LLM
LEVERAGING PROMPT ANALYTICS
The same way we think about product analytics, you can begin to capture prompt analytics across three types of feedback data:
Activation, whereby the user agrees with the initial prompt’s completion and continues their intended workflow or disagrees with the initial completion and drops off;
Qualitative, whereby the user is given an initial response and they can either regenerate the response or iterate their series of prompts to a completion of their liking;
Binary, whereby the user can click on the positive or negative CTA next to the prompt completion; if negative, you can ask the end user to provide an annotation like answering “what type of response were you expecting?”.
All three types should be reviewed by the prompt engineer or research scientist for model QA. Eventually your user’s interactive data will elicit a comprehensive set of prompts to run model evals for model comparison when retraining your models.
STEP 3: EMPOWER A MULTIDISCIPLINARY TEAM FOR PRODUCT DECISIONS
As you’ve probably gathered by now, building a product with LLMs is not just dynamic whereby each prompt completion is different but it is also iterative whereby each model deployment presents new challenges in evaluating its efficacy and product strengths. As you continue to design for user control and trust, creating a diverse team is important for making future product decisions.
To help evaluate these opportunities and potential benefits, create a multidisciplinary team to review how the product is providing value and leveraging LLMs.
Product, prompt, and model decisions should be made together in close collaboration. One as the user advocate or vertical domain expert, second as the prompt engineer, LLM whisperer or studious prompt librarian, and the third holding the engineer hat aka someone who understands your technical architecture deeply:
Problem Definition - The voice of the user that identifies the Jobs To Be Done, exploring how prompts and LLMs can be applied to drive deeper integration, collaboration, and value for the end user;
Prompt Engineering - Advanced prompt design requires a prompt library custodian, someone who is working closely with the model and its versioning to ensure product excellence and quality feedback loops;
RLHF Engineering - To support the product and prompt iterations, the product requires building data infrastructure to collect the user’s product interactions, prompts, and feedback to advance the model from its initial “one size fits all” state to becoming increasingly more personalized and advanced based on user adoption.
CONCLUSION
We’re just at the beginning of LLMs being adopted as new features, new interfaces, and new standalone products. It’s incredibly exciting to be at the cutting edge - building a 0-to-1 product within a 0-to-1 industry. My hope is that this brief essay on LLMs as collaborators, inhabiting a persona, enabling feedback, and driving product excellence is useful to both those building as well as those curious about how computing might change. The more I work with LLMs, the more it becomes clear to me that we are steadily moving from "word processing" to "work processing," where all of us will be managing a specialized group of LLMs for individual tasks, goals, and objectives, unlocking new opportunities we didn't know were possible.
Special thanks to Andy Young, Anna Bernstein, Ashvin Nair, Mehdi Ghissassi, and Sara Hooker for expanding my context window, and to the team at Craft for their continued collaboration.







